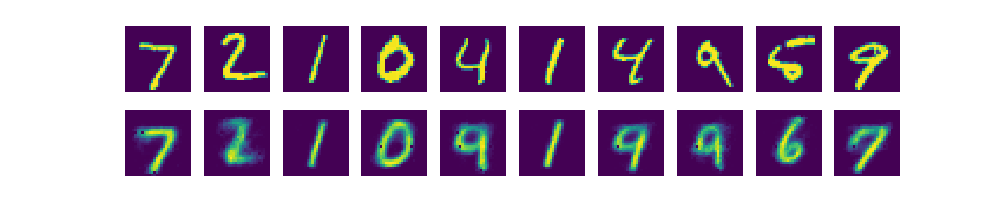Autoencoder是一种无监督的学习方法,通过编码过程自动提取数据的高阶特征,并用于分析与识别。
AutoEncoder(自编码)可以对数据进行非监督学习,首先通过encoder对数据进行压缩,然后再通过decoder对压缩数据进行恢复,并通过恢复数据与原始数据之间的误差来训练神经网络,从而可以实现网络对数据的特征提取。网络提取的中间压缩数据有点类似于PCA(主成分分析)的方法,都是从数据中提取有效信息。然后训练完成之后利用encoder部分便可以对数据进行特征提取,得到的特征数据可以用于后续的数据分析与识别。
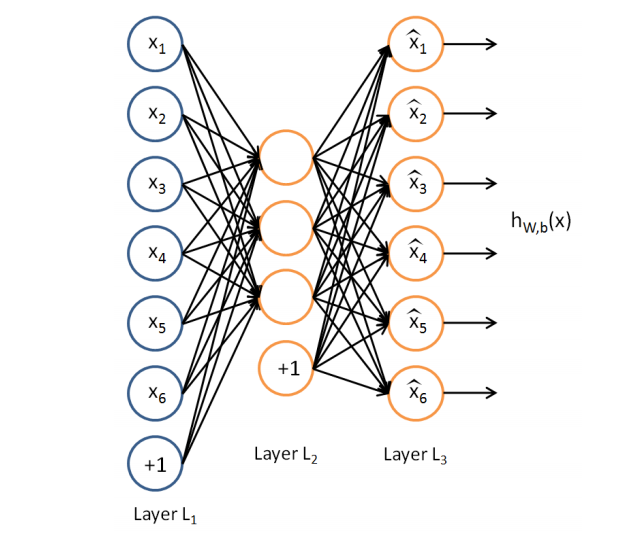
AutoEncoder的过程如下图,前半部分是Encoder结构,后半部分是Decoder部分。
AutoEncoder结构图
下面用TensorFlow来实现一个AutoEncoder网络。
今天用到的模块和版本号:
Python版本:3.5.3
Tensorflow版本:1.0.1
首先导入模块和数据
1 2 3 4 5 6 7
| import tensorflow as tf import numpy as np import matplotlib.pyplot as plt from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data", one_hot=False)
|
然后设置一些用到的参数的值
1 2 3 4 5 6 7 8 9 10 11 12 13
| learning_rate = 0.01 training_epochs = 20 batch_size = 256 display_step = 1 examples_to_show = 10 n_input = 784 n_hidden_1 = 128 n_hidden_2 = 64 n_hidden_3 = 10 n_hidden_4 = 2
|
AutoEncoder中设计了4个编码层和4个解码层,编码层和解码层一一对应。
然后设置AutoEncoder网络的权重和偏置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| weights = { 'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1],)), 'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2],)), 'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3],)), 'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4],)), 'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3],)), 'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2],)), 'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1],)), 'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input],)), } biases = { 'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])), 'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])), 'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])), 'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])), 'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])), 'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])), 'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])), 'decoder_b4': tf.Variable(tf.random_normal([n_input])), }
|
代码中,用tf.Variable()来创建变量,并用tf.truncated_normal()截尾正态分布随机值来初始化权重,并用tf.random_normal()正态分布来初始化偏置。
然后设计AutoEncoder的网络结构,记忆误差函数和训练函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
| def encoder(x): layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']), biases['encoder_b1'])) layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']), biases['encoder_b2'])) layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']), biases['encoder_b3'])) layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']), biases['encoder_b4']) return layer_4 def decoder(x): layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']), biases['decoder_b1'])) layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']), biases['decoder_b2'])) layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']), biases['decoder_b3'])) layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']), biases['decoder_b4'])) return layer_4 encoder_op = encoder(X) decoder_op = decoder(encoder_op) y_pred = decoder_op y_true = X cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2)) optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
|
代码中tf.matmul()用来计算数据与权值相乘的结果,tf.add()用来计算tf.matmul()得到结果加上偏置。在每个隐藏层之间加上tf.nn.sigmoid()作为激活函数(Activation function)
网络结构定义好之后就可以对网络进行训练了。
1 2 3 4 5 6 7 8 9 10 11 12
| sess = tf.Session() init = tf.global_variables_initializer() sess.run(init) total_batch = int(mnist.train.num_examples/batch_size) for epoch in range(training_epochs): for i in range(total_batch): batch_xs, batch_ys = mnist.train.next_batch(batch_size) _, c = sess.run([optimizer, cost], feed_dict={X: batch_xs}) print("Epoch:", '%02d' % (epoch+1),"cost=", "{:.9f}".format(c)) print("Optimization Finished!")
|
代码中,根据前面定义的参数,需要运行20次迭代来进行训练,在每次迭代过程中在将数据分批对网络参数进行优化,total_batch计算得到每次迭代中需要多少批数据(数据总量除以每一批需要的数据量),然后通过mnist.train.next_batch() 得到每一批的数据,并对网络参数进行优化。
然后用10组数据来测试一下网络解码之后的数据和原始数据之间的差别,并显出出来。
1 2 3 4 5 6 7 8 9
| encode_decode = sess.run(y_pred, feed_dict={X: mnist.test.images[:examples_to_show]}) f, a = plt.subplots(2, 10, figsize=(10, 2)) for i in range(examples_to_show): a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28))) a[1][i].imshow(np.reshape(encode_decode[i], (28, 28))) a[0][i].axis('off') a[1][i].axis('off') plt.show()
|
结果如下图,第一行是原始数据,第二行是Decoder解压缩之后的数据。
Decoder部分得到数据与原始数据对比
可以看出AutoEncoder解码得到的数据和原始数据的差别并不大。
然后只用AutoEncoder中的encoder部分来对测试数据进行计算,得到输出的二维数据并用散点图的方式显示在二维平面上。
1 2 3 4
| encoder_result = sess.run(encoder_op, feed_dict={X: mnist.test.images}) plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels) plt.colorbar() plt.show()
|
代码中plt.scatter()用来显示散点图,其中前两个参数表示数据的横坐标和纵坐标,第三个参数用来设置散点图的颜色。
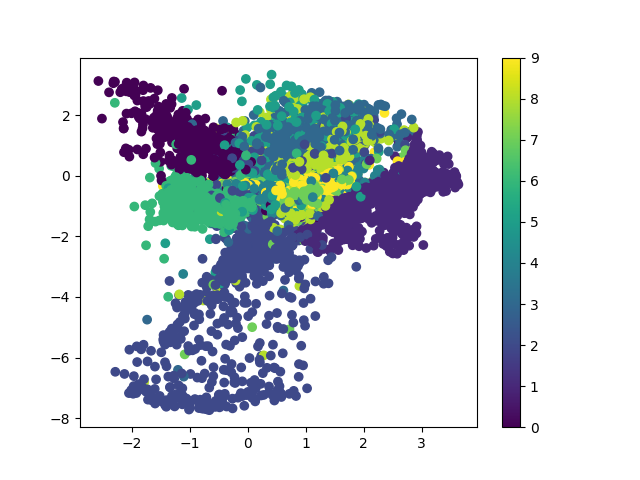
结果如下图:
压缩之后的数据分布
可以看出把数据压缩成二维之后可以提取数据中的部分有效信息。
后续也可以在得到的二位数据后使用普通神经网络或者其他分类方法对手写体数据进行分类。
参考资料: