今天介绍Deep Q Network的一个改进版本 DoubleDQN算法的原理和实现过程。
DQN算法中在计算需要通过在目标网络中得到下一个动作的状态值,但是由于目标网络的更新有一定的滞后性,所以导致算法中存在一定的误差。而Double DQN则是在估计网络中计算下一个动作,并用目标网络得到相应的状态值,这样可以提高算法的实时性。
在DQN中状态值的更新公式为:
$$
Y_t ^{DQN} = R_{t+1} + \gamma \max_a Q(S_{t+1},a;\theta_t^-)
$$
在Double DQN中,状态值的跟新公式为:
$$
Y_t ^{DoubleDQN} = R_{t+1} + \gamma Q(S_{t+1},arg\max_a Q(S_{t+1},a;\theta_t);\theta_t^-)
$$
下面通过编程来实现Double DQN算法。
用到的库如下:
Python:3.5.3
TensorFlow:1.0.1
gym:0.8.1
本次依然使用gym中的CartPole-v0的环境来实现算法。
代码大部分跟DQN的代码相同,只是在神经网络学习的时候状态值的更新方法不同,算法的学习部分如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
| def learn(self): if self.learn_step_counter % self.replace_target_iter == 0: self._replace_target_params() if self.memory_counter > self.memory_size: sample_index = np.random.choice(self.memory_size, size=self.batch_size) else: sample_index = np.random.choice(self.memory_counter, size=self.batch_size) batch_memory = self.memory[sample_index, :] q_next, q_eval4next = self.sess.run( [self.q_next, self.q_eval], feed_dict={self.s_: batch_memory[:, -self.n_features:], self.s: batch_memory[:, -self.n_features:]}) q_eval = self.sess.run(self.q_eval, {self.s: batch_memory[:, :self.n_features]}) q_target = q_eval.copy() batch_index = np.arange(self.batch_size, dtype=np.int32) eval_act_index = batch_memory[:, self.n_features].astype(int) reward = batch_memory[:, self.n_features + 1] if self.double_q: max_act4next = np.argmax(q_eval4next, axis=1) selected_q_next = q_next[batch_index, max_act4next] else: selected_q_next = np.max(q_next, axis=1) q_target[batch_index, eval_act_index] = reward + self.gamma * selected_q_next _, self.cost = self.sess.run([self._train_op, self.loss], feed_dict={self.s: batch_memory[:, :self.n_features], self.q_target: q_target}) self.cost_his.append(self.cost) self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max self.learn_step_counter += 1
|
其他的代码部分与DQN中的代码基本一致。
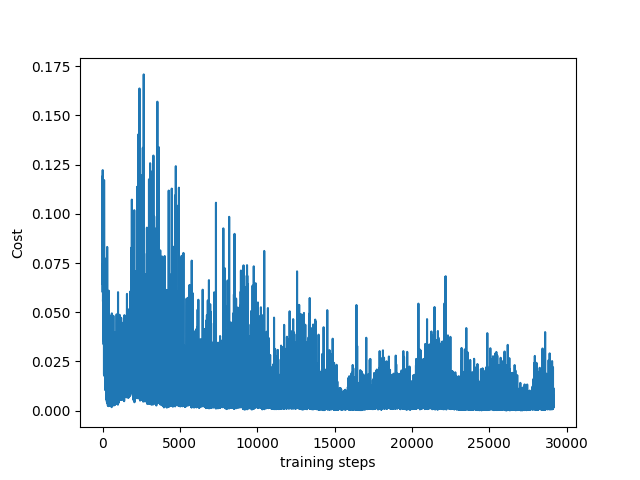
最终程序可疑达到预期的效果,损失函数图如下:
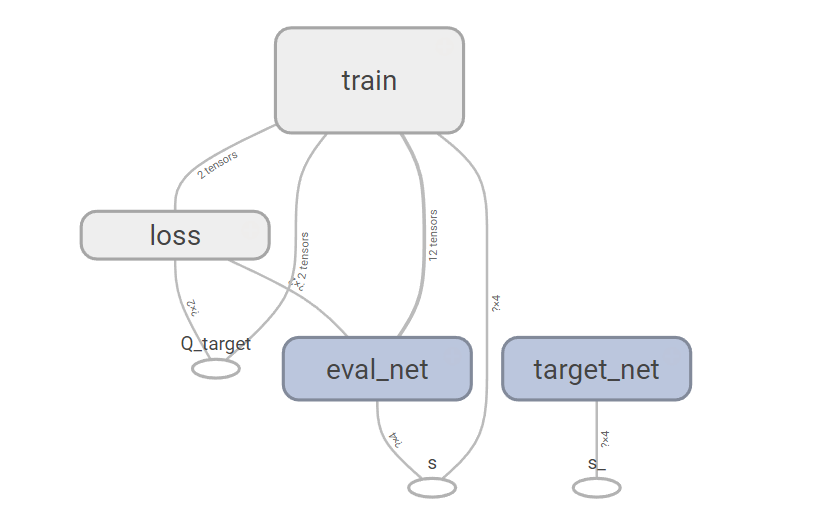
Double DQN的网络结构如下:
可以发现Double DQN的网络结构和Deep Q Network的网络结构相同。不同的是图中Q_target的更新方式。
参考资料: