本文介绍Deep Q Network的一种改进形式dueling DQN的设计与实现过程:
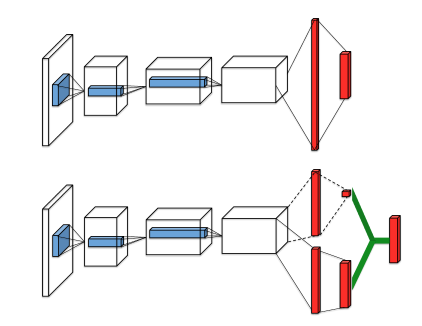
Dueling DQN将DQN中神经网络的中间层拆分成两个网络,一个为Value,一个为Advantage,然后将两个网络的值相加得到最终的网络的输出。
网络结构如下图所示:
在Dueling DQN中,神经网络的输出由下面的公式确定:
$$
Q(s,a;\theta,\alpha,\beta) = V(s;\theta,\beta)+A(s,a;\theta,\alpha)
$$
下面介绍Dueling DQN的具体实现过程:
用到的库如下:
Python:3.5.3
TensorFlow:1.0.1
gym:0.8.1
本文依旧用到gym中的CartPole-v0来完成算法。
代码大部分与DQN的代码相似,只是建立网络模型的部分不同,神将网络结构设计的代码部分如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
| def _build_net(self): def build_layers(s, c_names, n_l1, w_initializer, b_initializer): with tf.variable_scope('l1'): w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names) b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names) l1 = tf.nn.relu(tf.matmul(s, w1) + b1) with tf.variable_scope('Value'): w2 = tf.get_variable('w2', [n_l1, 1], initializer=w_initializer, collections=c_names) b2 = tf.get_variable('b2', [1, 1], initializer=b_initializer, collections=c_names) self.V = tf.matmul(l1, w2) + b2 with tf.variable_scope('Advantage'): w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names) b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names) self.A = tf.matmul(l1, w2) + b2 with tf.variable_scope('Q'): out = self.V + (self.A - tf.reduce_mean(self.A, axis=1, keep_dims=True)) return out
|
其他部分的代码与DQN中的代码基本相似。
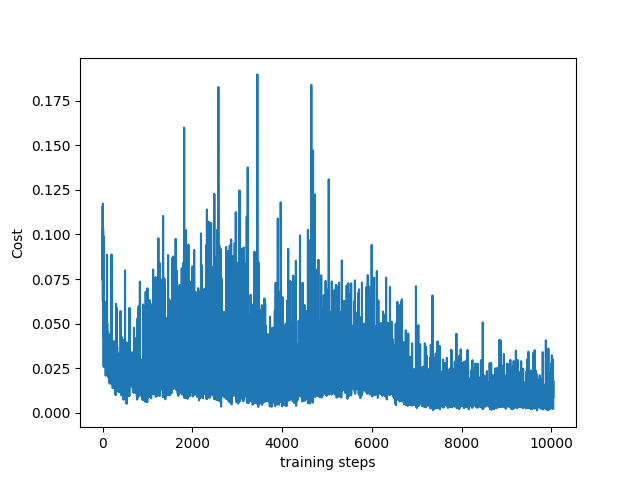
最终运行程序可以得到如下的损失函数:
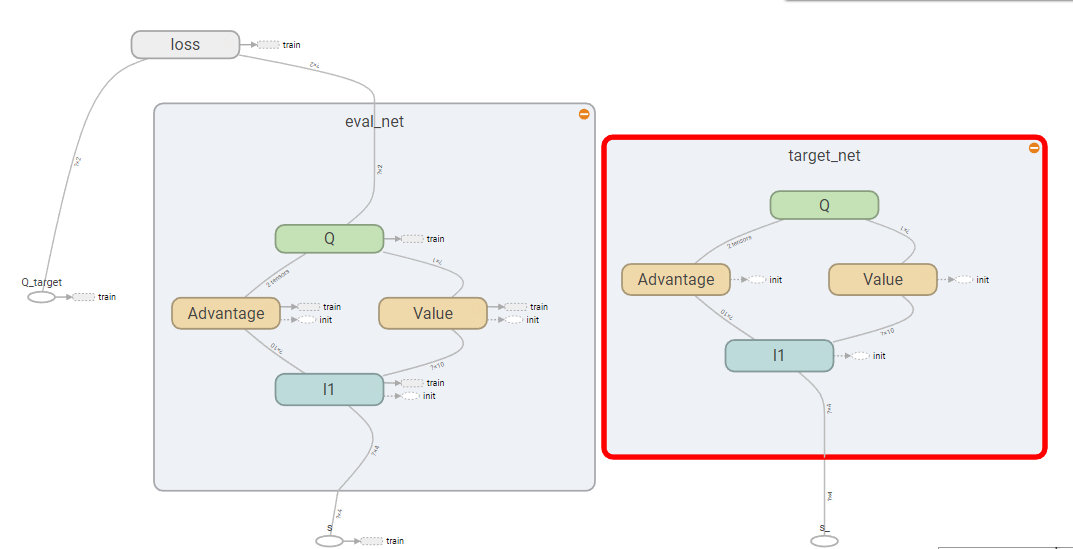
Dueling DQN的网络结构如下图:
Dueling DQN网络结构
DQN网络结构
从结构图中可以看到,Dueling DQN中将DQN中的l2节点改变成了Advantage,Value和Q三个结构。
参考资料: